overfitting(过拟合)是2025年机器学习与人工智能领域新手最需要关注的模型误差陷阱。本文系统解读overfitting现象、成因与检测方式,并剖析5大业界强力避免overfitting方法(早停法、数据扩增、正则化、特征选择、集成学习),辅以最新AI云平台与实用工具推荐,帮助新手有效提升模型泛化能力,为AI实战打下坚实基础。

overfitting是什么?机器学习发展下的新手最大难题
过拟合的定义与现象
overfitting指的是机器学习模型对训练数据“学得太好”,反而无法对未知数据进行有效预测。模型不但学了数据中的真实规律,还把训练数据里的噪音(noise)也视为必须记忆的模式。
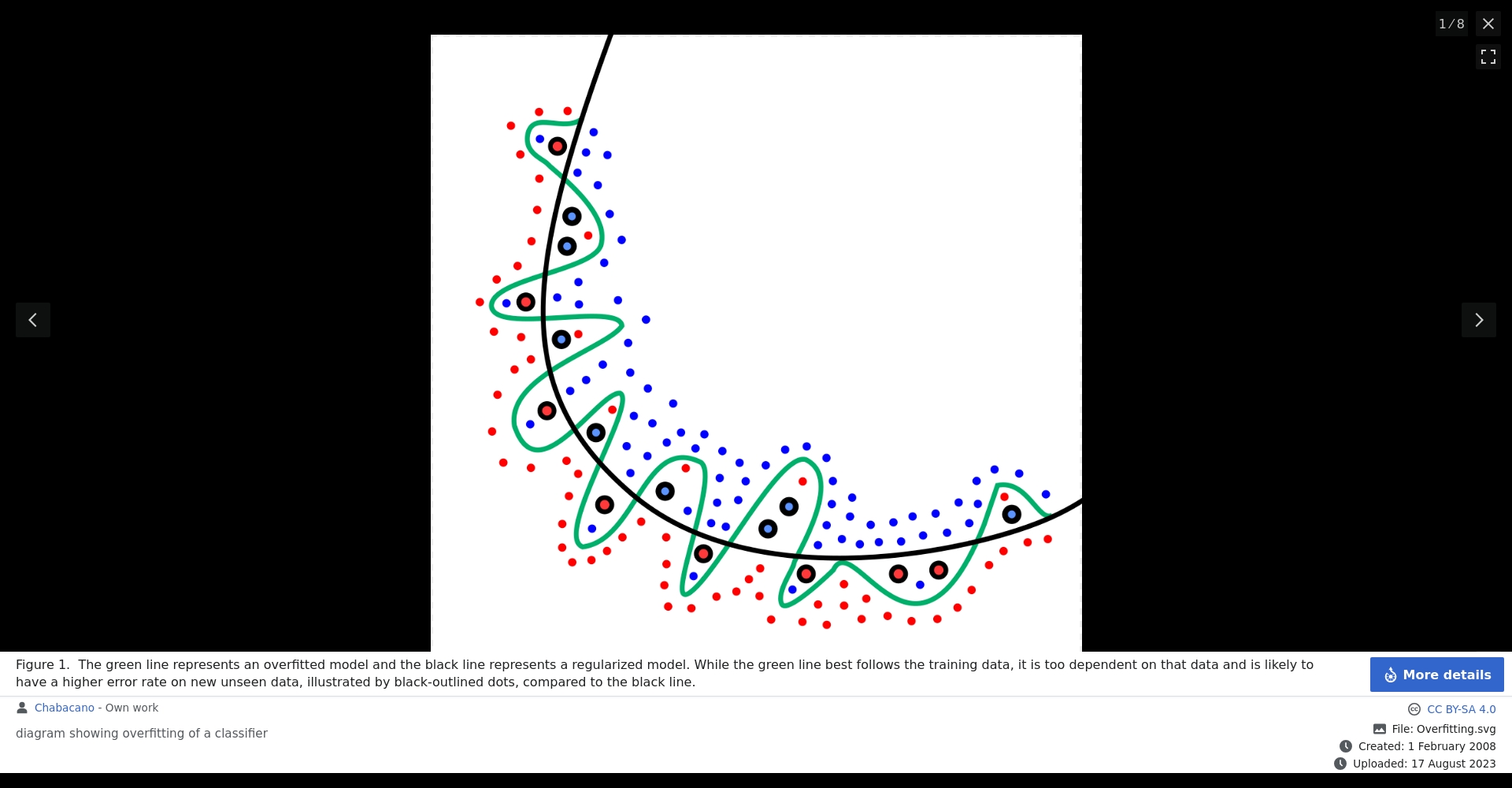
overfitting会导致模型在训练集表现极佳,但遇到新数据时准确率骤降,失去推理与预测价值。2025年,随着深度学习广泛应用于图像识别、NLP等领域,overfitting问题愈发重要。
overfitting常见原因
- 训练数据集过小或样本不足
- 数据内含大量无意义噪音
- 模型训练时长过长
- 模型结构过于复杂
overfitting是“高方差低偏差”型典型错误,与之相对的是“underfitting”(欠拟合)。
如何判断模型发生overfitting?
训练集与测试集表现不一致
若模型在训练集上准确率近100%,但在测试集明显变差,就是overfitting警讯。通常,需划出部分数据做验证或测试集评估模型泛化。
k-fold交叉验证
k-fold交叉验证是检测overfitting最常用方法。数据集被等分为K份,轮流做测试与训练取平均表现,检验模型稳健性。现代云平台如Amazon SageMaker能自动分离与预警。
2025年机器学习新手必知的5个有效避免overfitting方法
以下为当前业界主流有效overfitting预防手段总览:
| 预防方法 | 主要作用 | 适用情境 | 常用工具/平台 |
|---|---|---|---|
| 早停法(Early Stopping) | 防止训练过头,降低overfitting | 神经网络深度学习训练过程 | TensorFlow, Keras |
| 数据扩增(Data Augmentation) | 增加训练数据多样性 | 图像识别、语音、NLP | Augmentor, NLPAug |
| 正则化(Regularization) | 降低模型复杂度,防止权重过大 | 线性/非线性AI模型 | Scikit-learn, PyTorch |
| 特征选择(Feature Selection) | 删无用输入、降冗余 | 分类、预测类模型 | Feature-engine, XGBoost |
| 集成学习(Ensembling) | 多模型组合抗干扰 | 高方差决策树、分类回归 | LightGBM, CatBoost |

早停法(Early Stopping)
早停法是在训练过程中自动监控验证集表现,提前终止训练避免过拟合。Keras、TensorFlow等框架均内置该机制。
许多国际AI竞赛冠军模型均采用精细early stopping调控,2025年已是主流方案。
数据扩增(Data Augmentation)
通过微调、变化原始数据(如图像旋转、文本替换),人工增加样本多样性,有效防止模型死记特定数据细节。
标准化工具如Albumentations、NLPAug等可自动批量生成扩增样本。
正则化(Regularization)
在损失函数中增加“惩罚项”,限制参数过度扩张,抑制模型复杂度,是AI工程和竞赛中的必备手段。主流包括:
- L1正则(提升特征稀疏性)
- L2正则(限制权重幅度)
- Dropout(神经网络单元随机失活)
特征选择(Feature Selection)
自动筛选有效输入变量,排除冗余杂质,极大提升模型简洁性和泛化力。Boosting类算法如XGBoost, LightGBM自带该功能。
集成学习(Ensembling)
通过整合多个模型的判断提升整体稳定性和抗干扰力,是对抗高方差overfitting的强大武器。主流方式包括Bagging、Boosting和Stacking。

机器学习overfitting前后案例对比
| 案例/步骤 | overfitting处理前 | overfitting处理后(采用策略) |
|---|---|---|
| 图像猫狗分类(小样本无扩增) | 训练集99%,测试集75% | 训练集96%,测试集提升到89% |
| 用户信用评分(特征冗余) | 类别过细,表现不稳 | 特征优选,准确率提升解释性更强 |
| 语音识别(过度训练) | 忽略背景噪音,误差高 | Dropout+扩增,模型表现更稳 |
2025年最值得推荐的overfitting检测与修正AI工具
| 工具/平台名称 | 功能亮点 | 链接 |
|---|---|---|
| Amazon SageMaker | 自动训练/验证切割,自动警示overfitting | SageMaker |
| IBM watsonx.ai | 企业级训练与模型参数优化 | watsonx.ai |
| TensorFlow/Keras | 内置early stopping、正则化、扩增等模块 | TensorFlow |
| Scikit-learn | 丰富正则、特征筛选、交叉验证工具 | Scikit-learn |
| LightGBM/XGBoost | 集成学习+特征筛选+抗overfitting | LightGBM、XGBoost |
生成式AI与机器学习已进入爆发时期,模型泛化力将决定AI能否落地应用。充分理解overfitting本质、掌握核心防范检测技术、善用主流开源与云端工具,是2025每位AI新手的必备核心能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...